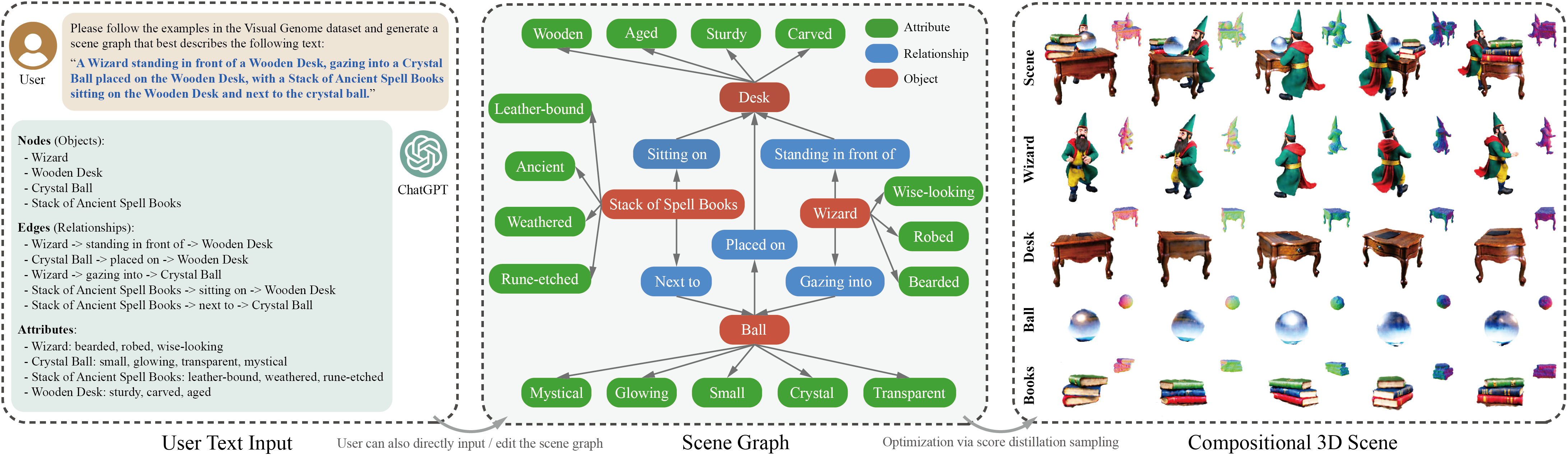
We present GraphDreamer, the first framework capable of generating compositional 3D scenes from scene graphs, where objects are represented as nodes and their relationships as edges. Our method makes better use of the pretrained text-to-image diffusion model by exploiting node and edge information in scene graphs, and is able to fully disentangle different objects without image-level supervision. To avoid manual scene graph creation, we design a text prompt for GPT-4 to generate scene graphs based on text inputs. Our comprehensive evaluation validates the effectiveness of GraphDreamer in generating compositional 3D scenes with both high fidelity and semantic accuracy.
Consider the task of text-grounded 3D generation. Existing methods take a plain text description of a 3D scene as input and consider the scene as a whole. This approach can be problematic for scenes with multiple objects, as the describing text becomes very long and complicated. The vectorized text embeddings inherently suffer from attribute confusion and guidance collapse.

Compositional modeling shows promise in addressing these problems. A straightforward solution to compositionality is to explicitly position objects within a set of 3D bounding boxes. However, this approach relies on the restrictive assumption that there is no overlap between object boxes, which often does not hold in practice.
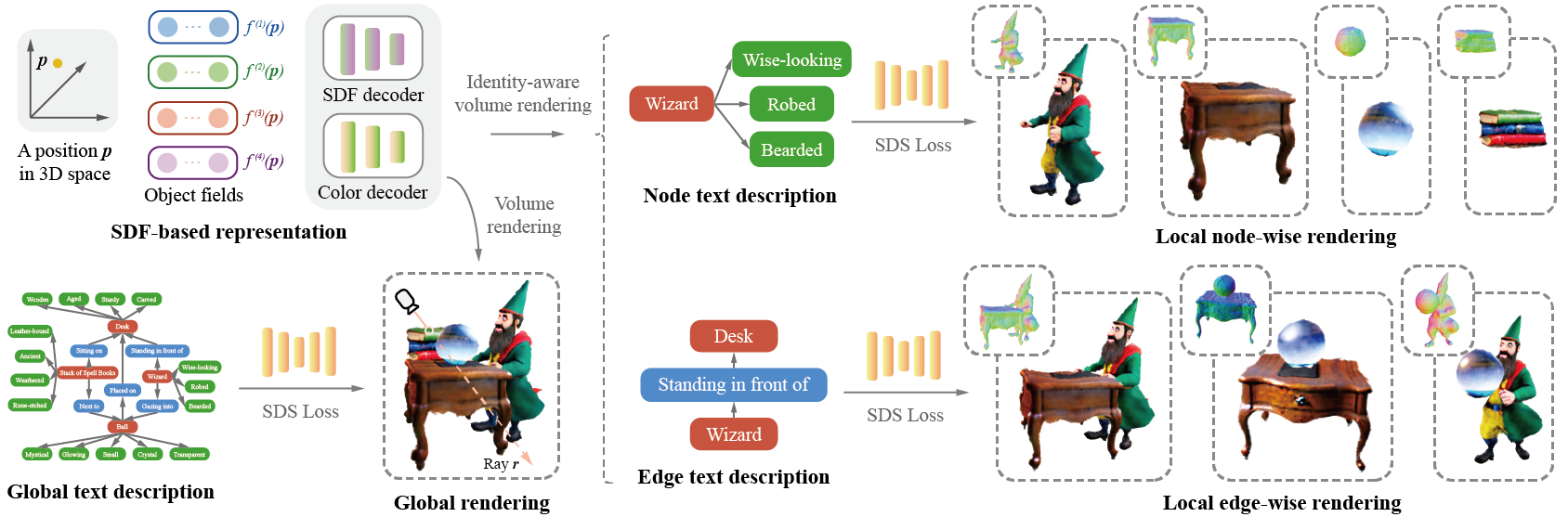
Main insight: a scene graph, with its nodes and edges clearly defining objects and object relationships, is a semantically more precise representation of a scene. Moreover, it inherently possesses the property of decomposability, allowing it to be readily decomposed into nodes (objects) and edges (relationships) without imposing any restrictive no-overlap assumption. GraphDreamer jointly supervises the generation at the object, relationship, and global levels, by leveraging the nodes, edges, and the entire graph for grounding.
To save the effort of building a scene graph from scratch, the scene graph can be generated by a language model (e.g., ChatGPT) from a user text input.
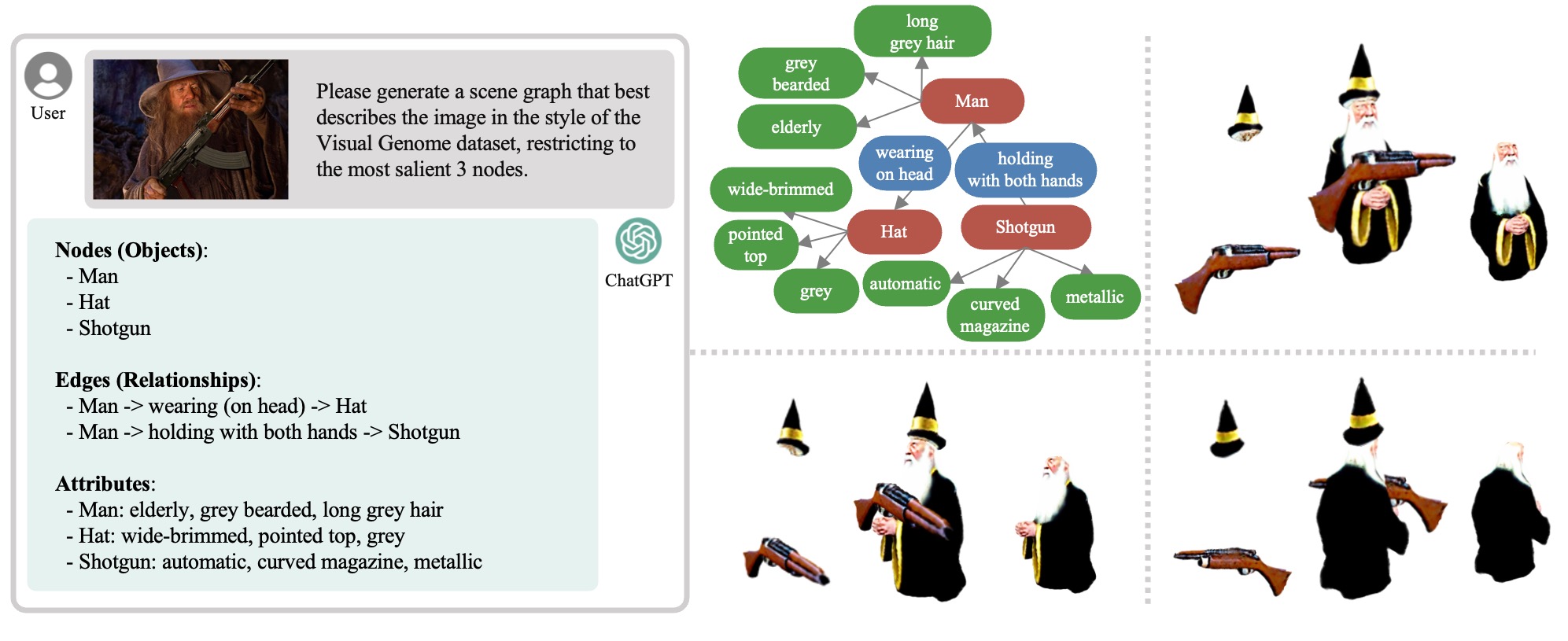
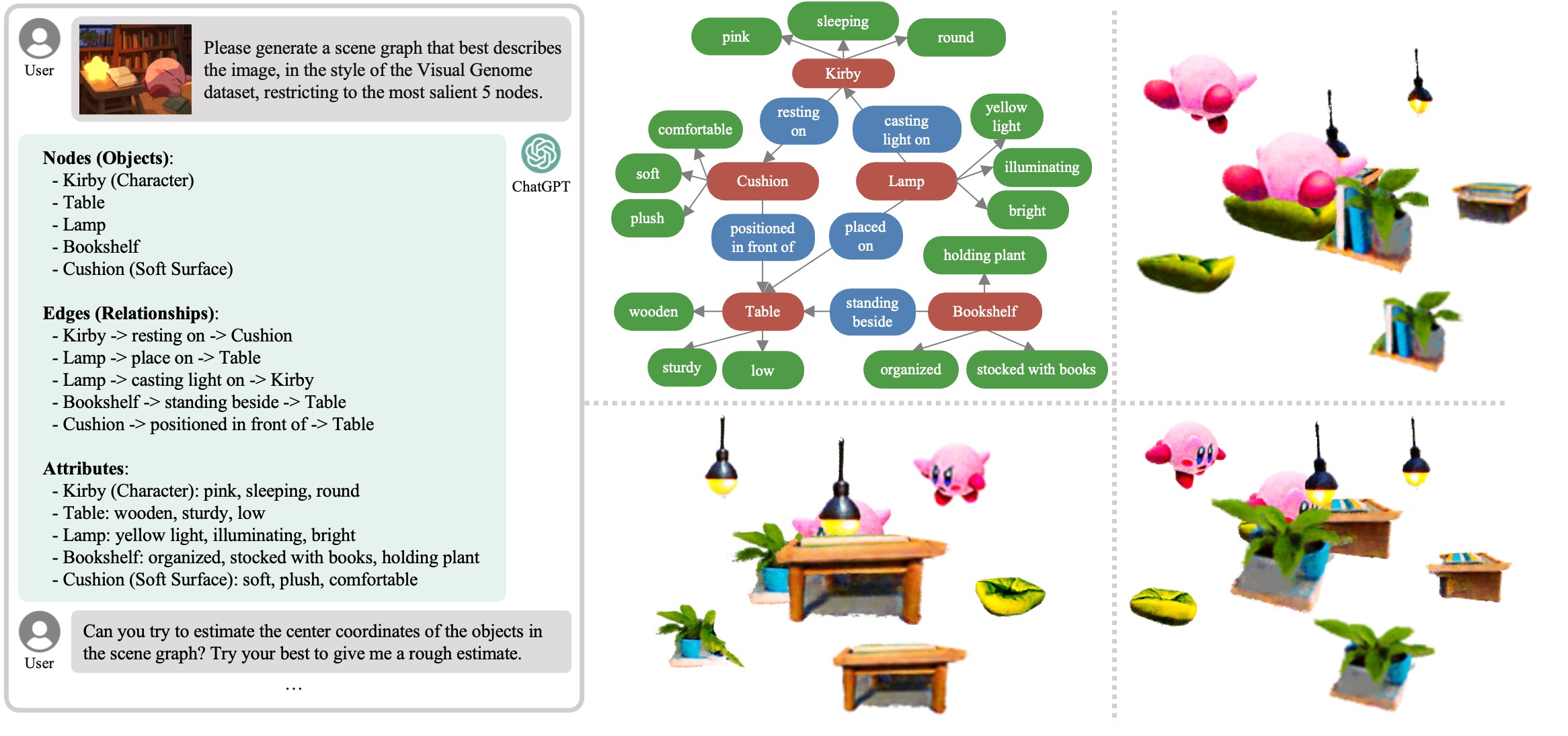
Using GraphDreamer, we can inverse the semantics in a given image into a 3D scene, by extracting a scene graph directly from an input image with GPT4V, restricting the nodes present to the most salient ones.
To inverse more complex semantics with more salient nodes in an image, we can ask GPT to provide with center coordinates for each object and initialize the SDF-based objects as spheres centered at these coordinates.
The authors extend their thanks to Zehao Yu and Stefano Esposito for their invaluable feedback on the initial draft. Our thanks also go to Yao Feng, Zhen Liu, Zeju Qiu, Yandong Wen, and Yuliang Xiu for their proofreading of the final draft and for their insightful suggestions which enhanced the quality of this paper. Additionally, we appreciate the assistance of those who participated in our user study. Weiyang Liu and Bernhard Schölkopf was supported by the German Federal Ministry of Education and Research (BMBF): Tübingen AI Center, FKZ: 01IS18039B, and by the Machine Learning Cluster of Excellence, the German Research Foundation (DFG): SFB 1233, Robust Vision: Inference Principles and Neural Mechanisms, TP XX, project number: 276693517. Andreas Geiger and Anpei Chen were supported by the ERC Starting Grant LEGO-3D (850533) and the DFG EXC number 2064/1 - project number 390727645.
@Inproceedings{gao2024graphdreamer,
author = {Gao, Gege and Liu, Weiyang and Chen, Anpei and Geiger, Andreas and Schölkopf, Bernhard},
title = {GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}